
7-9 Creating A Simple 2D Game For Reinforcement Learning (5)
今天終於要進入訓練的階段啦,這篇文章特別長唷。首先,建立一個如下圖的簡單的訓練場景。
本次主要訓練的目標:學會『跳過平台』。
所以大家會看到這個訓練場景就只有一個台階,讓AI學會跳躍以後,再放到更複雜的場景中測試。
 如不懂該如何建立上述的場景,請自行參考前四篇文章唷:
如不懂該如何建立上述的場景,請自行參考前四篇文章唷:
https://3dactionrpg.blogspot.com/2018/07/7-5-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-6-7-5-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-7-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-8-creating-simple-2d-game-for.html
接下來,要在專案內匯入ML-Agents相關的程式,可以到Github上下載,並確認至少包含『Editor』、『Plugins』、『Scripts』資料夾。
Github網址:https://github.com/Unity-Technologies/ml-agents

設置TensorFlowSharp插件
接著,需要安裝TensorFlowSharp才能使用Internal Brain模式。請到此網址下載:
https://s3.amazonaws.com/unity-ml-agents/0.3/TFSharpPlugin.unitypackage
下載完後,請自行匯入到Unity。
匯入後可能遇到的錯誤
假如遇到類似下圖的錯誤訊息:The type or namespace name `Google' could not be found. Are you missing an assembly reference?

請到Player Setting內,將Scripting Runtime Version設定為.NET 4.x Equivalent唷,修改設定後,Unity會自動要求重新啟動。

然後也請順便新增Scripting Define Symbols,加上『ENABLE_TENSORFLOW』,如果這一欄位原本已經有其他數值,請使用『;』進行區分。

接下來,如果還遇到下面這個錯誤訊息:
Unloading broken assembly Assets/ML-Agents/Plugins/Android/TensorFlowSharp.Android.dll, this assembly can cause crashes in the runtime

那請到該資料夾底下,選擇TensorFlowSharp.Android.dll,在Inspector視窗中將Editor取消勾選,按下Apply即可。

接著場景中新增一個Empty GameObject,名為CheckPoint。

並替CheckPoint設置一個Box Collider 2D,並如下圖設置CheckPoint的大小與位置。這是為了讓Player觸碰到CheckPoint以後,再重新回到原點使用的。

新增Academy
根據官方對Academy的描述如下:
『Academy 對象可在場景中協調 ML-Agents 並驅動模擬中的決策部分。每個 ML-Agent 場景需要一個 Academy 實例。由於 Academy 基類是抽象的,即使不需要對特定環境使用任何方法,您也必須創建自己的子類。』
接著我們新增一個PlatformerAcademy,由於這是基本範例,這邊我只單純繼承Academy,然後在Inspector設定所需的參數即可。

然後在場景中新增PlatformerAcademy物件,並設定相關參數。
Max Steps:每執行幾步會進行一次的狀態終結,並保存數據。我這邊設定10000。
Width:執行訓練時的視窗寬度。
Height:執行訓練時的視窗高度。
======以下設定我都保持預設======
Quality Level:渲染的質量(越高越好)。
Time Scale:訓練速度(越高越快)。
Target Frame Rate:設定FPS(盡量維持)。


在Brain中,可設定Vector Observation,Visual Observation,Vector Action,Brain Type。
我的設定為,Vector Observation的Space Size設為2。Brain Type設為Player。Discrete Player Actions的Size設為1,然後設定Key為Z,其Value為1。
首先說明Vector Observation,引用官方說明:
『Agent會將我們收集的信息發送給 Brain,由 Brain 使用這些信息來做決策。當您訓練 agent(或使用經過訓練的模型)時,數據將作為特徵向量輸入到神經網絡中。為了讓 agent 成功學習某個任務,我們需要提供正確的信息。為了決定要收集哪些信息,一個好的經驗法則是考慮您在計算問題的分析解決方案時需要用到什麼。』
我們的範例中會使用兩個觀察值,一個用來判斷Player是否在地面上,一個用來判斷Player的眼前是否遇到障礙物。這部分會在後續的程式碼撰寫上進行解說。
再來,Brain Type分為四種:Player、Heuristic、External、Internal。
Player:你可以設定一些KeyCode來修改環境參數,比方說KeyCode.Up,訓練參數的值為1,當你按下鍵盤的上鍵時,Agent就會輸入1給Brain。
Heuristic:啟發式,可以自己撰寫一些演算法去控制AI。
External:外部訓練模式,訓練一個模型儲存成二進制檔案。
Internal:內部模式,讀取訓練好的二進制檔案,執行模型。

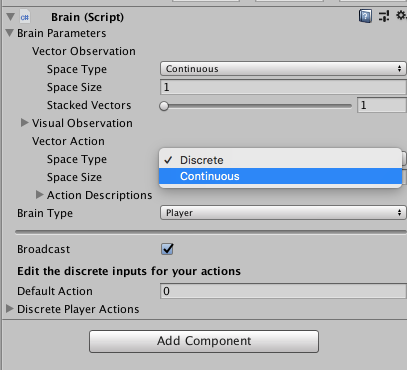
另外,特別說明在Vector Action的Space Type,可進行Discrete與Continuous的設定。
Discrete:離散的,如果我們要輸入給Brain進行操作的參數是整數。比方說,我們使用鍵盤Z代表跳躍,所以按下鍵盤Z的時候,傳給Brain一個整數值『1』。
Continuous:連續的,如果我們要輸入給Brain的參數是浮點數。比方說使用虛擬搖桿,最常用的做法是在X或Y給予不同移動程度的浮點數,所以使用虛擬搖桿,還能控制Player的移動速度。
實現Agent
Agent用以實現強化學習的邏輯,接著我們一步一步來撰寫邏輯的程式吧。
首先,我們要在地板的Collider身上加Tag,如下圖選擇Add Tag選項。

然後新增一個Tag名稱為Ground。

新增完Tag以後,需要自行將每一個地面的GameObject加上名為Ground的Tag。

在新增Agents前,我們還要修改過去撰寫的PlayerMovement.cs程式。首先新增MoveFront與MoveBack方法,這是開放給Agents用來移動Player的方法。

然後,讓我們把Update裡面控制Player的所有程式都註解掉,以免影響到Agents。

新增一個CheckPoint.cs,用來判斷Player是否觸發到重置學習環境的Trigger。

並在場景中的CheckPoint物件中加入Script。

記得Player也要設置Tag,這樣才能被CheckPoint偵測到。

接著,新增一個PlatformerAgent.cs,繼承Agent類,並設置相關初始屬性。

Override初始化Agent的方法,在初始化階段紀錄現在的Player位置為initPosition。

觀測環境
撰寫判斷Player面前是否有牆壁的方法。

撰寫判斷Player腳底下是否為地面的方法。

上述兩個方法都會使用到的RaycastHit的方法,我使用RaycastHit2D偵測射線上的Collider2D的Tag。

接著Override CollectObservations方法,該方法為設置Agents的觀察值,如同前面所說,我們必須輸入觀察值到神經網路中,才能判斷不同的輸入值,最後所帶來的結果是否為好的解。而這邊我們讓神經網路知道,Player會觀察地面,以及前面是否有牆。

獎勵
引用官方對於獎勵一詞的解釋:
『Reinforcement learning(強化學習)需要獎勵。應在 AgentAction() 函數中分配獎勵。學習算法使用在模擬和學習過程的每個步驟中分配給 agent 的獎勵來確定是否為 agent 提供了最佳動作。您會希望 agent 完成分配的任務時獎勵 agent,而在 agent 徹底失敗時懲罰 agent。有時,您可以通過一些子獎勵來鼓勵幫助 agent 完成任務的行為,從而加快訓練速度。例如,如果 agent 在某個步驟中靠近目標,則獎勵系統會提供小獎勵,並會在每個步驟提供很小的負獎勵來促使快速完成其任務。』
所以,在本章範例中,如果Player正常移動,則會給予獎勵1分。如果Player在遇到障礙物的時候進行跳躍,也會給予獎勵1分。但如果Player一直亂跳的話,就會給予負獎勵5分,用來懲罰當Player隨意地亂跳。


然後當Player抵達終點時,將 agent 標記為完成狀態,agent將停止活動直到重置為止。可以設置 Inspector 中的 Agent.ResetOnDone 屬性, 以便當它被標記為完成狀態時,立即重置 agent。你也可以等待 Academy 自己重置環境(如我們前面介紹Academy時所說的Max Steps參數)。

最後,我們在場景中建立一個Agent物件。

然後如下圖加入PlatformerAgent.cs,並設置Agent的參數。

然後我們可以先執行遊戲看看,是否有遇到問題。
都沒問題以後,就讓我們開始跑訓練吧!記得,要將Brain換成External。

然後在Player Setting中,記得勾選Run In Background,並將Display Resolution Dialog設定為Disabled,才不會每次訓練時,都會跳出解析度的詢問視窗。

Product Name可以自己定義,要記下來,這邊我設定為2D-ML-Example。

進入ml-agents的python資料夾,用jupyter開啟Basics.ipynb的設定。

如下圖,將env_name設定為2D-ML-Example,然後存檔。
 然後選擇TrainingScene,並按下Build。
然後選擇TrainingScene,並按下Build。

Build完成。

輸入指令開始訓練。由於我在更前面的章節已講述過安裝與訓練的細節,便不再贅述,有需要的話請參考以前的文章唷:
7-2 Setting Up Unity ML-Agents On Windows

開始訓練以後,就會自動跳出訓練視窗,看見遊戲中的小狐狸正在瘋狂的亂跑亂跳。


我另外新增一個TF-Models資料夾儲存Model檔案。

然後回到我們的SampleScene,同樣要新增Academy、Brain、Agent,這邊也不再贅述了。

Brain Type的部分選擇Internal,然後將剛剛的Model檔案拉進Graph Model參數中。如果選擇Internal有出現錯誤的話,那你可能沒有正常安裝TensorFlowSharp插件,或者設置參數,請回到本文的最上面觀看說明。

接著來執行遊戲吧,可以看見小狐狸很聰明地跳過障礙,這可不是我在操作喔XD。我想,我們下一章應該要來點更難的障礙了。

以下提供本次修改的所有程式碼:
CheckPoint.cs:
PlatformerAcademy.cs:
PlayerMovement.cs:
PlatformerAgent.cs:
本次主要訓練的目標:學會『跳過平台』。
所以大家會看到這個訓練場景就只有一個台階,讓AI學會跳躍以後,再放到更複雜的場景中測試。

https://3dactionrpg.blogspot.com/2018/07/7-5-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-6-7-5-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-7-creating-simple-2d-game-for.html
https://3dactionrpg.blogspot.com/2018/07/7-8-creating-simple-2d-game-for.html
接下來,要在專案內匯入ML-Agents相關的程式,可以到Github上下載,並確認至少包含『Editor』、『Plugins』、『Scripts』資料夾。
Github網址:https://github.com/Unity-Technologies/ml-agents

設置TensorFlowSharp插件
接著,需要安裝TensorFlowSharp才能使用Internal Brain模式。請到此網址下載:
https://s3.amazonaws.com/unity-ml-agents/0.3/TFSharpPlugin.unitypackage
下載完後,請自行匯入到Unity。
匯入後可能遇到的錯誤
假如遇到類似下圖的錯誤訊息:The type or namespace name `Google' could not be found. Are you missing an assembly reference?

請到Player Setting內,將Scripting Runtime Version設定為.NET 4.x Equivalent唷,修改設定後,Unity會自動要求重新啟動。

然後也請順便新增Scripting Define Symbols,加上『ENABLE_TENSORFLOW』,如果這一欄位原本已經有其他數值,請使用『;』進行區分。

接下來,如果還遇到下面這個錯誤訊息:
Unloading broken assembly Assets/ML-Agents/Plugins/Android/TensorFlowSharp.Android.dll, this assembly can cause crashes in the runtime

那請到該資料夾底下,選擇TensorFlowSharp.Android.dll,在Inspector視窗中將Editor取消勾選,按下Apply即可。

接著場景中新增一個Empty GameObject,名為CheckPoint。

並替CheckPoint設置一個Box Collider 2D,並如下圖設置CheckPoint的大小與位置。這是為了讓Player觸碰到CheckPoint以後,再重新回到原點使用的。

新增Academy
根據官方對Academy的描述如下:
『Academy 對象可在場景中協調 ML-Agents 並驅動模擬中的決策部分。每個 ML-Agent 場景需要一個 Academy 實例。由於 Academy 基類是抽象的,即使不需要對特定環境使用任何方法,您也必須創建自己的子類。』
接著我們新增一個PlatformerAcademy,由於這是基本範例,這邊我只單純繼承Academy,然後在Inspector設定所需的參數即可。

然後在場景中新增PlatformerAcademy物件,並設定相關參數。
Max Steps:每執行幾步會進行一次的狀態終結,並保存數據。我這邊設定10000。
Width:執行訓練時的視窗寬度。
Height:執行訓練時的視窗高度。
======以下設定我都保持預設======
Quality Level:渲染的質量(越高越好)。
Time Scale:訓練速度(越高越快)。
Target Frame Rate:設定FPS(盡量維持)。
Reset Parameters:每次重置時,根據設置的參數進行重置。
(未來如果有用到Reset Parameters的時候,會再進行更詳細的解說。)

新增Brain
然後在PlatformerAcademy底下新增PlatformerBrain。
在Brain中,可設定Vector Observation,Visual Observation,Vector Action,Brain Type。
我的設定為,Vector Observation的Space Size設為2。Brain Type設為Player。Discrete Player Actions的Size設為1,然後設定Key為Z,其Value為1。
首先說明Vector Observation,引用官方說明:
『Agent會將我們收集的信息發送給 Brain,由 Brain 使用這些信息來做決策。當您訓練 agent(或使用經過訓練的模型)時,數據將作為特徵向量輸入到神經網絡中。為了讓 agent 成功學習某個任務,我們需要提供正確的信息。為了決定要收集哪些信息,一個好的經驗法則是考慮您在計算問題的分析解決方案時需要用到什麼。』
我們的範例中會使用兩個觀察值,一個用來判斷Player是否在地面上,一個用來判斷Player的眼前是否遇到障礙物。這部分會在後續的程式碼撰寫上進行解說。
再來,Brain Type分為四種:Player、Heuristic、External、Internal。
Player:你可以設定一些KeyCode來修改環境參數,比方說KeyCode.Up,訓練參數的值為1,當你按下鍵盤的上鍵時,Agent就會輸入1給Brain。
Heuristic:啟發式,可以自己撰寫一些演算法去控制AI。
External:外部訓練模式,訓練一個模型儲存成二進制檔案。
Internal:內部模式,讀取訓練好的二進制檔案,執行模型。

另外,特別說明在Vector Action的Space Type,可進行Discrete與Continuous的設定。
Discrete:離散的,如果我們要輸入給Brain進行操作的參數是整數。比方說,我們使用鍵盤Z代表跳躍,所以按下鍵盤Z的時候,傳給Brain一個整數值『1』。
Continuous:連續的,如果我們要輸入給Brain的參數是浮點數。比方說使用虛擬搖桿,最常用的做法是在X或Y給予不同移動程度的浮點數,所以使用虛擬搖桿,還能控制Player的移動速度。

實現Agent
Agent用以實現強化學習的邏輯,接著我們一步一步來撰寫邏輯的程式吧。
首先,我們要在地板的Collider身上加Tag,如下圖選擇Add Tag選項。

然後新增一個Tag名稱為Ground。

新增完Tag以後,需要自行將每一個地面的GameObject加上名為Ground的Tag。

在新增Agents前,我們還要修改過去撰寫的PlayerMovement.cs程式。首先新增MoveFront與MoveBack方法,這是開放給Agents用來移動Player的方法。

然後,讓我們把Update裡面控制Player的所有程式都註解掉,以免影響到Agents。

新增一個CheckPoint.cs,用來判斷Player是否觸發到重置學習環境的Trigger。

並在場景中的CheckPoint物件中加入Script。

記得Player也要設置Tag,這樣才能被CheckPoint偵測到。

接著,新增一個PlatformerAgent.cs,繼承Agent類,並設置相關初始屬性。

Override初始化Agent的方法,在初始化階段紀錄現在的Player位置為initPosition。

觀測環境
撰寫判斷Player面前是否有牆壁的方法。

撰寫判斷Player腳底下是否為地面的方法。

上述兩個方法都會使用到的RaycastHit的方法,我使用RaycastHit2D偵測射線上的Collider2D的Tag。

接著Override CollectObservations方法,該方法為設置Agents的觀察值,如同前面所說,我們必須輸入觀察值到神經網路中,才能判斷不同的輸入值,最後所帶來的結果是否為好的解。而這邊我們讓神經網路知道,Player會觀察地面,以及前面是否有牆。

獎勵
引用官方對於獎勵一詞的解釋:
『Reinforcement learning(強化學習)需要獎勵。應在 AgentAction() 函數中分配獎勵。學習算法使用在模擬和學習過程的每個步驟中分配給 agent 的獎勵來確定是否為 agent 提供了最佳動作。您會希望 agent 完成分配的任務時獎勵 agent,而在 agent 徹底失敗時懲罰 agent。有時,您可以通過一些子獎勵來鼓勵幫助 agent 完成任務的行為,從而加快訓練速度。例如,如果 agent 在某個步驟中靠近目標,則獎勵系統會提供小獎勵,並會在每個步驟提供很小的負獎勵來促使快速完成其任務。』
所以,在本章範例中,如果Player正常移動,則會給予獎勵1分。如果Player在遇到障礙物的時候進行跳躍,也會給予獎勵1分。但如果Player一直亂跳的話,就會給予負獎勵5分,用來懲罰當Player隨意地亂跳。


然後當Player抵達終點時,將 agent 標記為完成狀態,agent將停止活動直到重置為止。可以設置 Inspector 中的 Agent.ResetOnDone 屬性, 以便當它被標記為完成狀態時,立即重置 agent。你也可以等待 Academy 自己重置環境(如我們前面介紹Academy時所說的Max Steps參數)。

最後,我們在場景中建立一個Agent物件。
然後如下圖加入PlatformerAgent.cs,並設置Agent的參數。

然後我們可以先執行遊戲看看,是否有遇到問題。
都沒問題以後,就讓我們開始跑訓練吧!記得,要將Brain換成External。

然後在Player Setting中,記得勾選Run In Background,並將Display Resolution Dialog設定為Disabled,才不會每次訓練時,都會跳出解析度的詢問視窗。

Product Name可以自己定義,要記下來,這邊我設定為2D-ML-Example。

進入ml-agents的python資料夾,用jupyter開啟Basics.ipynb的設定。

如下圖,將env_name設定為2D-ML-Example,然後存檔。


Build完成。

輸入指令開始訓練。由於我在更前面的章節已講述過安裝與訓練的細節,便不再贅述,有需要的話請參考以前的文章唷:
7-2 Setting Up Unity ML-Agents On Windows
7-3 Setting Up Unity ML-Agents On MacOS

開始訓練以後,就會自動跳出訓練視窗,看見遊戲中的小狐狸正在瘋狂的亂跑亂跳。

訓練完成以後,請將訓練模型的bytes檔放進Unity專案中。

我另外新增一個TF-Models資料夾儲存Model檔案。

然後回到我們的SampleScene,同樣要新增Academy、Brain、Agent,這邊也不再贅述了。

Brain Type的部分選擇Internal,然後將剛剛的Model檔案拉進Graph Model參數中。如果選擇Internal有出現錯誤的話,那你可能沒有正常安裝TensorFlowSharp插件,或者設置參數,請回到本文的最上面觀看說明。

接著來執行遊戲吧,可以看見小狐狸很聰明地跳過障礙,這可不是我在操作喔XD。我想,我們下一章應該要來點更難的障礙了。

以下提供本次修改的所有程式碼:
CheckPoint.cs:
using UnityEngine;
public class CheckPoint : MonoBehaviour
{
[HideInInspector] public bool enterCheckPoint;
private const string PLAYER_TAG = "Player";
private void OnTriggerEnter2D(Collider2D collision)
{
// 如果碰撞的物體是Player
if (collision.gameObject.tag.Equals(PLAYER_TAG))
{
enterCheckPoint = true;
}
}
private void OnTriggerExit2D(Collider2D collision)
{
// 如果碰撞的物體是Player
if (collision.gameObject.tag.Equals(PLAYER_TAG))
{
enterCheckPoint = false;
}
}
}
PlatformerAcademy.cs:
using MLAgents;
public class PlatformerAcademy : Academy {
}
PlayerMovement.cs:
using UnityEngine;
public class PlayerMovement : MonoBehaviour
{
[SerializeField] Rigidbody2D myRigidbody2D;
[SerializeField] Animator animator;
[SerializeField] float speed = 30;
[SerializeField] float jumpHeight = 2;
bool isGround = false;
const int MOVE_STOP = 0;
const int MOVE_RIGHT = 1;
const int MOVE_LEFT = -1;
const int RIGHT_DIRECTION = 0;
const int LEFT_DIRECTION = 1;
void Update()
{
// 按下方向鍵左鍵,或右鍵時進行移動,開啟Run動畫
//if (Input.GetKey(KeyCode.RightArrow))
//{
// Move(MOVE_RIGHT);
// ChangeDirection(RIGHT_DIRECTION);
// SetRunAnimator(true);
//}
//else if (Input.GetKey(KeyCode.LeftArrow))
//{
// Move(MOVE_LEFT);
// ChangeDirection(LEFT_DIRECTION);
// SetRunAnimator(true);
//}
//// 放開方向鍵左鍵或右鍵時關閉Run動畫
//else if (Input.GetKeyUp(KeyCode.RightArrow) || Input.GetKeyUp(KeyCode.LeftArrow))
//{
// Move(MOVE_STOP);
// SetRunAnimator(false);
//}
//// 按下Z鍵呼叫Jump方法,開啟Jump動畫
//if (Input.GetKey(KeyCode.Z))
//{
// Jump();
// SetJumpAnimator(true);
//}
//// 當Player回到地面時,關閉Jump動畫
//if (isGround)
//{
// SetJumpAnimator(false);
//}
}
///
/// 對Agents開放的移動Player的方法
///
/// Movement.
public void MoveFront(int movement){
Move(movement);
ChangeDirection(RIGHT_DIRECTION);
SetRunAnimator(true);
}
///
/// 對Agents開放的移動Player的方法
///
/// Movement.
public void MoveBack(int movement){
Move(-movement);
ChangeDirection(LEFT_DIRECTION);
SetRunAnimator(true);
}
public void Jump()
{
// 當Player不在地面時,不要再設定Velocity
if (!isGround)
{
return;
}
// 設定Player的Velocity的Y值,即可讓Player跳起
Vector2 velocity = myRigidbody2D.velocity;
velocity.y = jumpHeight;
myRigidbody2D.velocity = velocity;
}
void Move(int i)
{
// 設定Player的Velocity的X值,即可讓Player移動
Vector2 velocity = myRigidbody2D.velocity;
velocity.x = i * speed * Time.deltaTime;
myRigidbody2D.velocity = velocity;
}
void ChangeDirection(int i)
{
// 若i為1則會將Y軸轉向180度,若i為0則會轉回原方向
// 藉此控制角色的轉向
transform.eulerAngles = new Vector3(0, 180 * i, 0);
}
void SetRunAnimator(bool isMove)
{
animator.SetBool("Run", isMove);
}
void SetJumpAnimator(bool isJump)
{
animator.SetBool("Jump", isJump);
}
private void OnCollisionStay2D(Collision2D collision)
{
//若接觸點的法線向量不為上的話,代表並非撞到地板
if (collision.contacts[0].normal != Vector2.up)
return;
isGround = true;
}
private void OnCollisionExit2D(Collision2D collision)
{
isGround = false;
}
}
PlatformerAgent.cs:
using UnityEngine;
using MLAgents;
public class PlatformerAgent : Agent
{
private const string GROUND_TAG = "Ground";
[SerializeField] private GameObject player;
[SerializeField] private CheckPoint goal;
[SerializeField] private PlayerMovement playerMovement;
private Vector2 initPosition;
///
/// 覆寫初始化Agent的方法
///
public override void InitializeAgent()
{
initPosition = player.transform.position;
}
///
/// 設置觀察量
///
public override void CollectObservations()
{
// 使用Player是否在地面上,以及是否碰到牆作為觀察值
// 觀察值用的是1和0
AddVectorObs(IsGround(player.transform.position) ? 1 : 0);
AddVectorObs(HasWallInFront(player.transform.position) ? 1 : 0);
}
///
/// 對Agent的具體操作放在這邊
///
/// Vector action.
/// Text action.
public override void AgentAction(float[] vectorAction, string textAction)
{
// 如果在地面上,就讓Player往前移動
if (IsGround(player.transform.position))
{
playerMovement.MoveFront(1);
}
int action = Mathf.FloorToInt(vectorAction[0]);
// 如果Agent沒有進行跳躍,是正常往前移動
if (action == 0 && IsGround(player.transform.position))
{
// 在路上走的話能得到獎勵1分
SetReward(1f);
}
else if (action == 1 && IsGround(player.transform.position))
{
// 判斷前面是否有牆
if (HasWallInFront(player.transform.position))
{
// 有牆的情況下跳躍,得獎勵1分
AddReward(1f);
}
else
{
// 沒有牆的情況下亂跳,扣獎勵5分
AddReward(-5f);
}
playerMovement.Jump();
}
// 如果Player抵達終點
if (goal.enterCheckPoint)
{
Done();
}
}
///
/// 當Agent進行一次結算的時候,會對Agent進行Reset操作
///
public override void AgentReset()
{
player.transform.position = initPosition;
}
///
/// Agents the on done.
///
public override void AgentOnDone()
{
}
///
/// 如果Player前面是牆壁
///
/// true , if wall in front was hased, false otherwise.
/// 如果Player在地面上
///
/// true , if ground was ised, false otherwise.
/// Detects the raycast hit.
///
/// true , if raycast hit was detected, false otherwise.
留言
張貼留言